Data in DNA
DNA as a Data Storage Method and the Algorithms for Encrypting Data into DNA
DNA as a Data Storage Method and the Algorithms for Encrypting Data into DNA
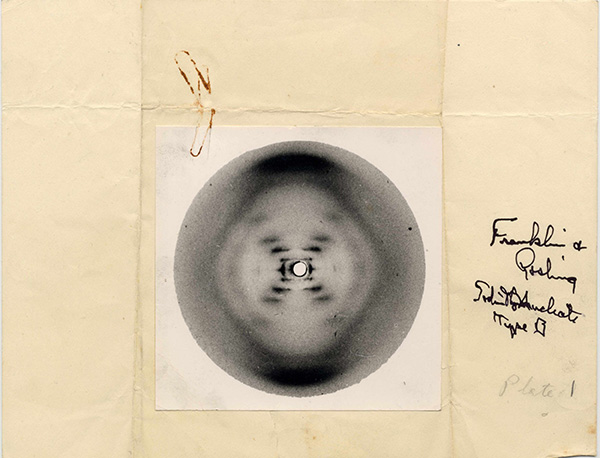
Image shown above: Photo 51, an early photo of DNA that was pivitol to our modern understanding of the double-helix model.
Internet big + AI even bigger. Need smaller solutions, running out of space. Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat. https://www.science.org/content/article/dna-could-store-all-worlds-data-one-room
DNA can last for thousands of years (cite and compare this) Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat.
Much lower than traditional methods. Lorem ipsum dolorem sit amet consectetur elit. Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat.
Data loss from outdated mediums. Who will know how to use a VHS in 100 years? Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis. Tempus leo eu aenean sed diam urna tempor.
https://wyss.harvard.edu/news/save-it-in-dna/
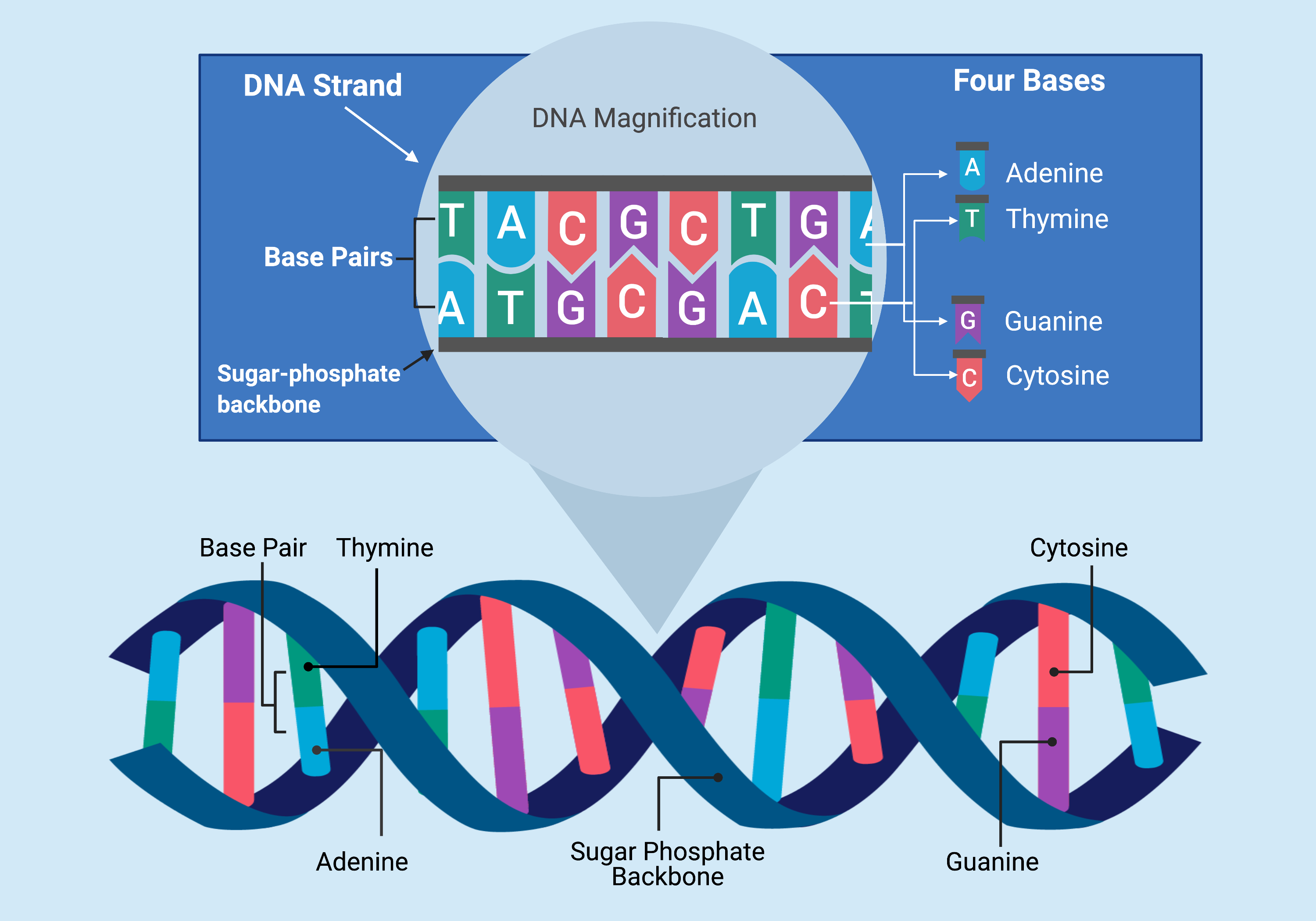
The main part of DNA that we'll be focusing on are its nitrogenous bases, the way DNA stores information. These four bases are 'Adenine', 'Guanine', 'Cytosine' and 'Thymine', also often referred to as 'A', 'G', 'C', and 'T'. These bases are complimentary: Adenine binds with Thymine, and Guanine binds with Cytosine.
DNA is read as triplets of bases called 'codons', that each encode either a command (like 'start reading' or 'stop reading'), or an amino acid, the building blocks of proteins.

Notice the 'U' base in the above chart. This is because the codon chart is using mRNA, not DNA. mRNA is a DNA-like substance that has the base Uracil (U) instead of Thymine, as well as a slightly differnet sugar base. When DNA is copied to create amino acids, mRNA, or 'Messanger RNA' stores the copied information and transports it to the ribosome for it to be read and translated into a string of amino acids (aka a polypeptide chain).
PCR, or 'Polymerase Chain Reaction', is a technique to increase the amount of ('amplify') a specific sequence of DNA, especially to make it easier to read.

Short strands of DNA that are complimentary to the desired sequence, called 'primers', are used to identify the correct sequence of DNA. These primers bind to the end of the sequence, and then DNA polymerase adds nucleotides to the ends of the primers, duplicating the DNA sequence.
https://www.britannica.com/science/polymerase-chain-reactionLorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis. Tempus leo eu aenean sed diam urna tempor.
Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis.
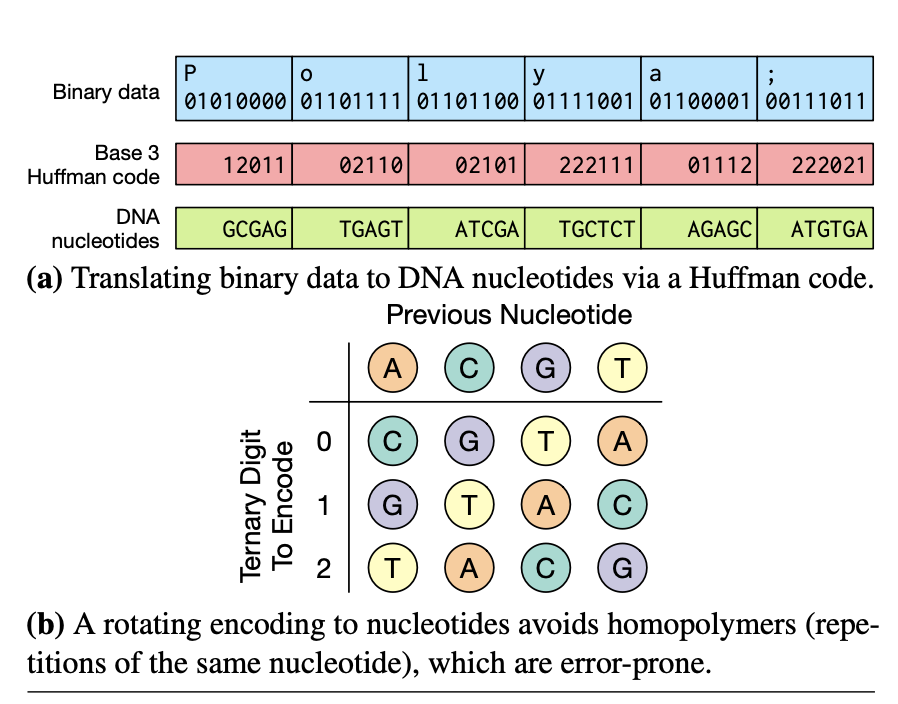
Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis.
Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis. Tempus leo eu aenean sed diam urna tempor. Pulvinar vivamus fringilla lacus nec metus bibendum egestas. Iaculis massa nisl malesuada lacinia integer nunc posuere. Ut hendrerit semper vel class aptent taciti sociosqu. Ad litora torquent per conubia nostra inceptos himenaeos.

Lorem sit amet delorum
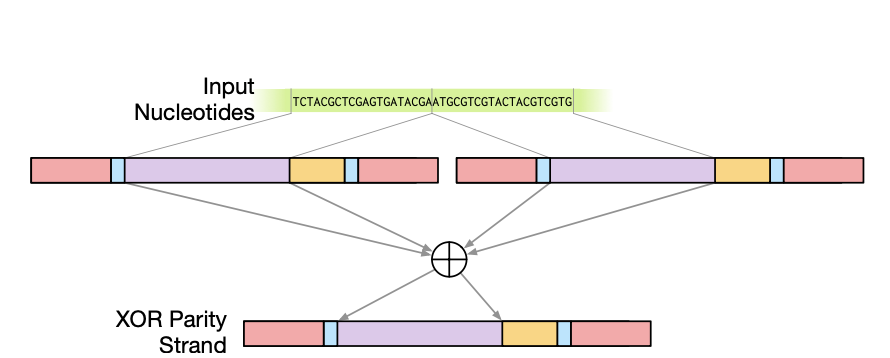
Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis. Tempus leo eu aenean sed diam urna tempor. Pulvinar vivamus fringilla lacus nec metus bibendum egestas. Iaculis massa nisl malesuada lacinia integer nunc posuere. Ut hendrerit semper vel class aptent taciti sociosqu. Ad litora torquent per conubia nostra inceptos himenaeos.
Yadzi et. al: https://pmc.ncbi.nlm.nih.gov/articles/PMC4585656/
What is Reed-Solomon Encoding?
Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis. Tempus leo eu aenean sed diam urna tempor. Pulvinar vivamus fringilla lacus nec metus bibendum egestas. Iaculis massa nisl malesuada lacinia integer nunc posuere.
Grass et. al: https://onlinelibrary.wiley.com/doi/full/10.1002/anie.201411378
The following types of sequences cause issues with the synthesis & sequencing processes:
It appears that there are two main approaches to avoiding these sequences. There is 'constrained coding', which specifically generates sequences that avoid these issues, and then 'unconstrained coding', which simply creates pseudo-random sequences.
Weindel et. al: https://ieeexplore.ieee.org/document/11164904
Lorem ipsum dolor sit amet consectetur adipiscing elit.
Pseudo-Randomness
Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat.
https://www.nature.com/articles/nbt.4079#MOESM4Lorem ipsum dolor sit amet consectetur adipiscing elit. Quisque faucibus ex sapien vitae pellentesque sem placerat. In id cursus mi pretium tellus duis convallis.